Trie 树是什么样的数据结构?有哪些应用场景?
数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。

什么是Trie树
Trie树,又叫字典树、前缀树(Prefix Tree)、单词查找树 或 键树,是一种多叉树结构。如下图:
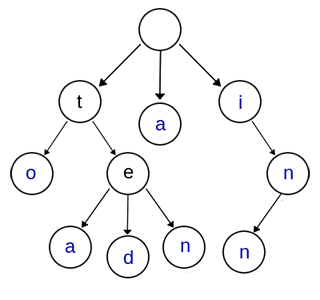
上图是一棵Trie树,表示了关键字集合{“a”, “to”, “tea”, “ted”, “ten”, “i”, “in”, “inn”} 。从上图可以归纳出Trie树的基本性质:
- 根节点不包含字符,除根节点外的每一个子节点都包含一个字符。
- 从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符互不相同。
通常在实现的时候,会在节点结构中设置一个标志,用来标记该结点处是否构成一个单词(关键字)。
可以看出,Trie树的关键字一般都是字符串,而且Trie树把每个关键字保存在一条路径上,而不是一个结点中。
另外,两个有公共前缀的关键字,在Trie树中前缀部分的路径相同,所以Trie树又叫做前缀树(Prefix Tree)。
 Trie树的优缺点
Trie树的优缺点
Trie树的核心思想是空间换时间,利用字符串的公共前缀来减少无谓的字符串比较以达到提高查询效率的目的。
优点:
- 插入和查询的效率很高,都为O(m)O(m),其中 mm 是待插入/查询的字符串的长度。
- 关于查询,会有人说 hash 表时间复杂度是O(1)O(1)不是更快?但是,哈希搜索的效率通常取决于 hash 函数的好坏,若一个坏的 hash 函数导致很多的冲突,效率并不一定比Trie树高。
- Trie树中不同的关键字不会产生冲突。
- Trie树只有在允许一个关键字关联多个值的情况下才有类似hash碰撞发生。
- Trie树不用求 hash 值,对短字符串有更快的速度。通常,求hash值也是需要遍历字符串的。
- Trie树可以对关键字按字典序排序。
缺点:
 Trie树的应用
Trie树的应用
1、字符串检索
检索/查询功能是Trie树*原始的功能。思路就是从根节点开始一个一个字符进行比较:
- 如果沿路比较,发现不同的字符,则表示该字符串在集合中不存在。
- 如果所有的字符全部比较完并且全部相同,还需判断*后一个节点的标志位(标记该节点是否代表一个关键字)。
-
struct trie_node
-
{
-
bool isKey; // 标记该节点是否代表一个关键字
-
trie_node *children[26]; // 各个子节点
-
};
-
2、词频统计
Trie树常被搜索引擎系统用于文本词频统计 。
-
struct trie_node
-
{
-
int count; // 记录该节点代表的单词的个数
-
trie_node *children[26]; // 各个子节点
-
};
-
思路:为了实现词频统计,我们修改了节点结构,用一个整型变量count来计数。对每一个关键字执行插入操作,若已存在,计数加1,若不存在,插入后count置1。
注意:*、第二种应用也都可以用 hash table 来做。
3、字符串排序
Trie树可以对大量字符串按字典序进行排序,思路也很简单:遍历一次所有关键字,将它们全部插入trie树,树的每个结点的所有儿子很显然地按照字母表排序,然后先序遍历输出Trie树中所有关键字即可。
4、前缀匹配
例如:找出一个字符串集合中所有以ab开头的字符串。我们只需要用所有字符串构造一个trie树,然后输出以a->b->开头的路径上的关键字即可。
trie树前缀匹配常用于搜索提示。如当输入一个网址,可以自动搜索出可能的选择。当没有完全匹配的搜索结果,可以返回前缀*相似的可能。
5、作为其他数据结构和算法的辅助结构
如后缀树,AC自动机等。

Trie树的实现
这里为了方便,我们假设所有的关键字都由 a-z 的字母组成。
下面是 trie 树的一种典型实现:
-
#include <iostream>
-
#include <string>
-
using namespace std;
-
-
#define ALPHABET_SIZE 26
-
-
typedef struct trie_node
-
{
-
int count; // 记录该节点代表的单词的个数
-
trie_node *children[ALPHABET_SIZE]; // 各个子节点
-
}*trie;
-
-
trie_node* create_trie_node()
-
{
-
trie_node* pNode = new trie_node();
-
pNode->count = 0;
-
for(int i=0; i<ALPHABET_SIZE; ++i)
-
pNode->children[i] = NULL;
-
return pNode;
-
}
-
-
void trie_insert(trie root, char* key)
-
{
-
trie_node* node = root;
-
char* p = key;
-
while(*p)
-
{
-
if(node->children[*p-‘a’] == NULL)
-
{
-
node->children[*p-‘a’] = create_trie_node();
-
}
-
node = node->children[*p-‘a’];
-
++p;
-
}
-
node->count += 1;
-
}
-
-
/**
-
* 查询:不存在返回0,存在返回出现的次数
-
*/
-
int trie_search(trie root, char* key)
-
{
-
trie_node* node = root;
-
char* p = key;
-
while(*p && node!=NULL)
-
{
-
node = node->children[*p-‘a’];
-
++p;
-
}
-
-
if(node == NULL)
-
return 0;
-
else
-
return node->count;
-
}
-
-
int main()
-
{
-
// 关键字集合
-
char keys[][8] = {“the”, “a”, “there”, “answer”, “any”, “by”, “bye”, “their”};
-
trie root = create_trie_node();
-
-
// 创建trie树
-
for(int i = 0; i < 8; i++)
-
trie_insert(root, keys[i]);
-
-
// 检索字符串
-
char s[][32] = {“Present in trie”, “Not present in trie”};
-
printf(“%s — %s\n”, “the”, trie_search(root, “the”)>0?s[0]:s[1]);
-
printf(“%s — %s\n”, “these”, trie_search(root, “these”)>0?s[0]:s[1]);
-
printf(“%s — %s\n”, “their”, trie_search(root, “their”)>0?s[0]:s[1]);
-
printf(“%s — %s\n”, “thaw”, trie_search(root, “thaw”)>0?s[0]:s[1]);
-
-
return 0;
-
}
-
对于Trie树,我们一般只实现插入和搜索操作。这段代码可以用来检索单词和统计词频。
博文链接:
blog.csdn.net/lisonglisonglisong/article/details/45584721
