5 分钟了解机器学习的特征工程
介绍
在我们进一步研究之前,我们需要定义机器学习中的特征。
如果您不熟悉机器学习,那么特征就是机器学习算法模型的输入。

什么是特征工程?
特征工程使用数学、统计学和领域知识从原始数据中提取有用的特征的方法。
例如,如果两个数字特征的比率对分类实例很重要,那么计算该比率并将其作为特征包含可能会提高模型质量。
例如有两个特征:平方米和公寓价格。您可能需要通过获取每平方米价格来创建特征以改进您的模型。
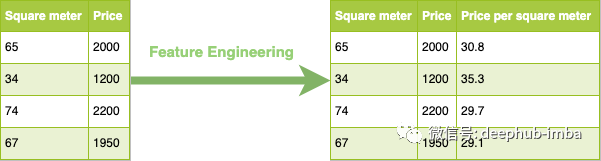
如何做特征工程?
让我们看看特征工程的不同策略。在本文中,我们不会看到所有方法,而是*流行的方法。添加和删除特征:
假设我们确实具有以下特征:
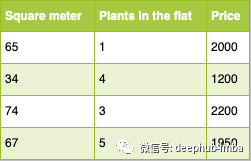
如果我们想预测公寓的价格,植物的数量可能无关紧要。在这种情况下,我们需要从机器学习模型中删除此功能,以免添加额外的噪音。
这种噪音被称为维度灾难。这意味着随着数据中特征数量的增加,构建良好模型所需的数据点数量呈指数增长。
我们需要选择哪些特征与我们的模型*相关。
将多个特征组合成一个特征:
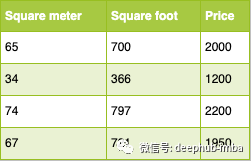
在上面的例子中,我们可以看到平方米和平方英尺实际上是相同的数据,但不是相同的单位。如果我们将其提供给我们的算法,它将必须了解平方米和平方英尺是相关的并且实际上是相同的特征。
这就是为什么我们需要决定采用哪种测量并只保留一个。
我们也可以有两个特征,狗的数量和猫的数量,并在动物数量下将它们组合起来。

尽管如此,结合这些功能并不是每次都是一个好主意。例如,在日期特征的情况下,可能是星期几很重要。
你需要记住质量胜于数量。
清理现有特征:
您需要保留您认为与模型相关的特征,以获取数据中的正确信号。
为此,您可以:
- 估算缺失值。
- 删除不尝试使用不具有代表性的数据点进行训练的异常值。
- 摆脱比例尺,例如,如果您有以厘米为单位的要素而其他一些以米为单位的要素,请尝试将所有要素都以厘米为单位进行转换。这称为规范化。
- 由于更容易的分布,转换倾斜的数据以使其更适合我们的模型。
分箱:
分箱是指您进行数值测量并将其转换为类别。
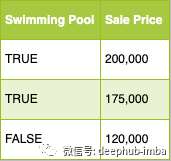
以下是房屋销售的示例:
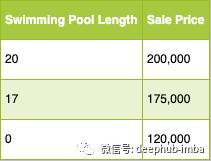
在那个例子中,我们可以假设销售价格取决于有游泳池的事实。
然后我们可以通过预处理数据并用布尔未来替换游泳池长度来简化我们的模型。
独热(One-hot)编码:
独热编码是一种以机器学习算法能够理解的方式表示分类数据的方式。
我们的模型理解数字但不理解字符串,这就是我们需要将字符串转换为数字的原因。但是,我们不能为我们的字符串分配随机数,因为我们的模型可能比小数字更重视大数字。这就是为什么我们要使用 one-hot 编码的原因。
以下是有关房屋销售的示例:
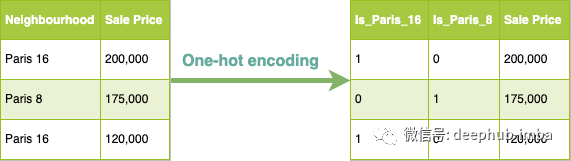
One-hot 编码对于用机器学习模型能够理解的简单数字数据替换分类数据很有用。
总结
特征工程将帮助您:
借助适当的特征,解决适当的业务案例问题。
提高机器学习算法的性能。
